Lucene词汇表和架构
Lucene诞生的目标是提供一个全文检索的功能库。基本概念:
-
文档(document):索引和搜索时使用的主要数据载体,包含一个或多个存有数据的字段。
-
字段(field):文档的一部分,包含名称和值两部分。
-
词(term):一个搜索单元,表示文本中的一个词。
-
标记(token):表示在字段文本中出现的词,由这个词的文本、开始和结束偏移量以及类型组成。
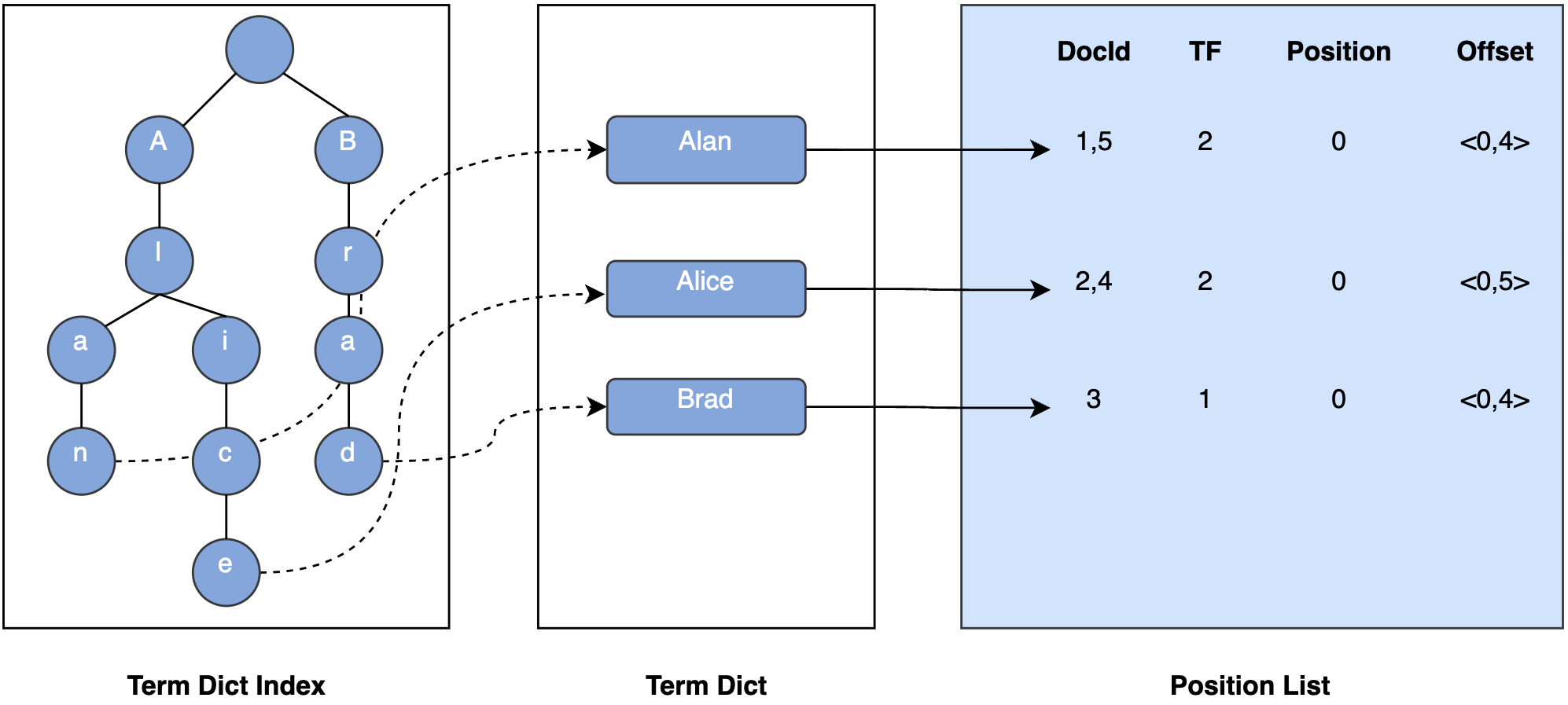
Lucene将所有信息写到**倒排索引(inverted index)**的结构中,倒排建立词与文档之间的映射。简单举个栗子,现有三个需要被索引的字段:『小明 足球』、『小红 足球』、『小光 羽毛球』,简化版的索引可以看成表中所示,执行非常高效快速的搜索。
| 词 | 计数 | 文档 |
|---|---|---|
| 小明 | 1 | <1> |
| 小红 | 1 | <2> |
| 小光 | 1 | <3> |
| 足球 | 2 | <1>,<2> |
| 羽毛球 | 1 | <3> |
每个索引分为多个"写一次读多次"的段(segment),每一个段本身都是一个倒排索引,建立索引时一个段写入磁盘就不能再更新,因此,被删除文档信息存在一个单独文件中( .del 文件),该段自身不被更新。当一个文档被删除时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
多个段可以通过**段合并(segment merge)**合并在一起,小段合并成大段,会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。检索大段比小段快,因为通过小段寻找和合并结果,比直接一个大段提供结果慢的多。
输入数据分析
数据转化成倒排索引,查询文本变成可被搜索的词,这个数据转化过程被称为分析。比如,car和cars在索引中被视为同一个,一些 字段用空格划分。分析的工作由分析器完成,由一个分词器(tokenizer)、0或多个标记过滤器(token filter)组成,也可以有0或多个字符映射器(character mapping)。
Lucene中的分词器把文本分割成多个标记,基本就是词加上一些额外信息,比如该词在原始文本中的位置和长度。分词器的处理结果称为标记流(token stream),它是一个接一个的标记, 准备被过滤器处理。
除了分词器,Lucene分析器包含零个或多个标记过滤器,用来处理标记流中的标记。下面是 一些过滤器的例子。
- 小写过滤器(lowercase filter):把所有的标记变成小写。
- 同义词过滤器(synonyms filter):基于基本的同义词规则,把一个标记换成另一个同义的标记。
- 多语言词干提取过滤器(multiple language stemming filter):减少标记(实际上是标记中的文本部分),得到词根或者基本形式,即词干。
过滤器是一个接一个处理的。所以我们通过使用多个过滤器,几乎可以达到无限的分析可能性。
最后,字符映射器对未经分析的文本起作用,它们在分词器之前工作。因此,我们可以很容 易地从文本的整体部分去除HTML标签而无需担心它们被标记。
索引和查询
建立索引时,Lucene会使用你选择的分析器来处理你的文档内容。当然,不同的字段可以使用不同的分析器,所以文档的名称字段可以和汇总字段做不同的分析。如果我们愿意,也可以不分析字段。
查询时,查询将被分析。但是,你也可以选择不分析。记住这一点很关键。有时你可能希望查询一个未经分析的字段,而有时你则希望有全文搜索的分析。如果我们查询LightRed这个词,标准分析器分析这个查询后,会去查询light和red;如果我们使用不经分析的查询类型,则会明确地查询LightRed这个词。
索引应该和查询词匹配。如果它们不匹配,Lucene 不会返回所需文档。比如,你在建立索引时使用了词干提取和小写,那你应该保证查询中的词也必须是词干和小写,否则你的查询不会返回任何结果。重要的是在索引和查询分析时,对所用标记过滤器保持相同的顺序,这样被分析出来的词是一样的。
分片
有一个概念经常混淆: 一个Lucene索引在Elasticsearch称作分片 。一个Elasticsearch索引是分片的集合。 当Elasticsearch在索引中搜索的时候,他发送查询到每一个属于索引的分片(Lucene 索引),合并每个分片的结果到一个全局的结果集。
分片组成
官方Bolg:lucene-index-files{:target="_blank"}
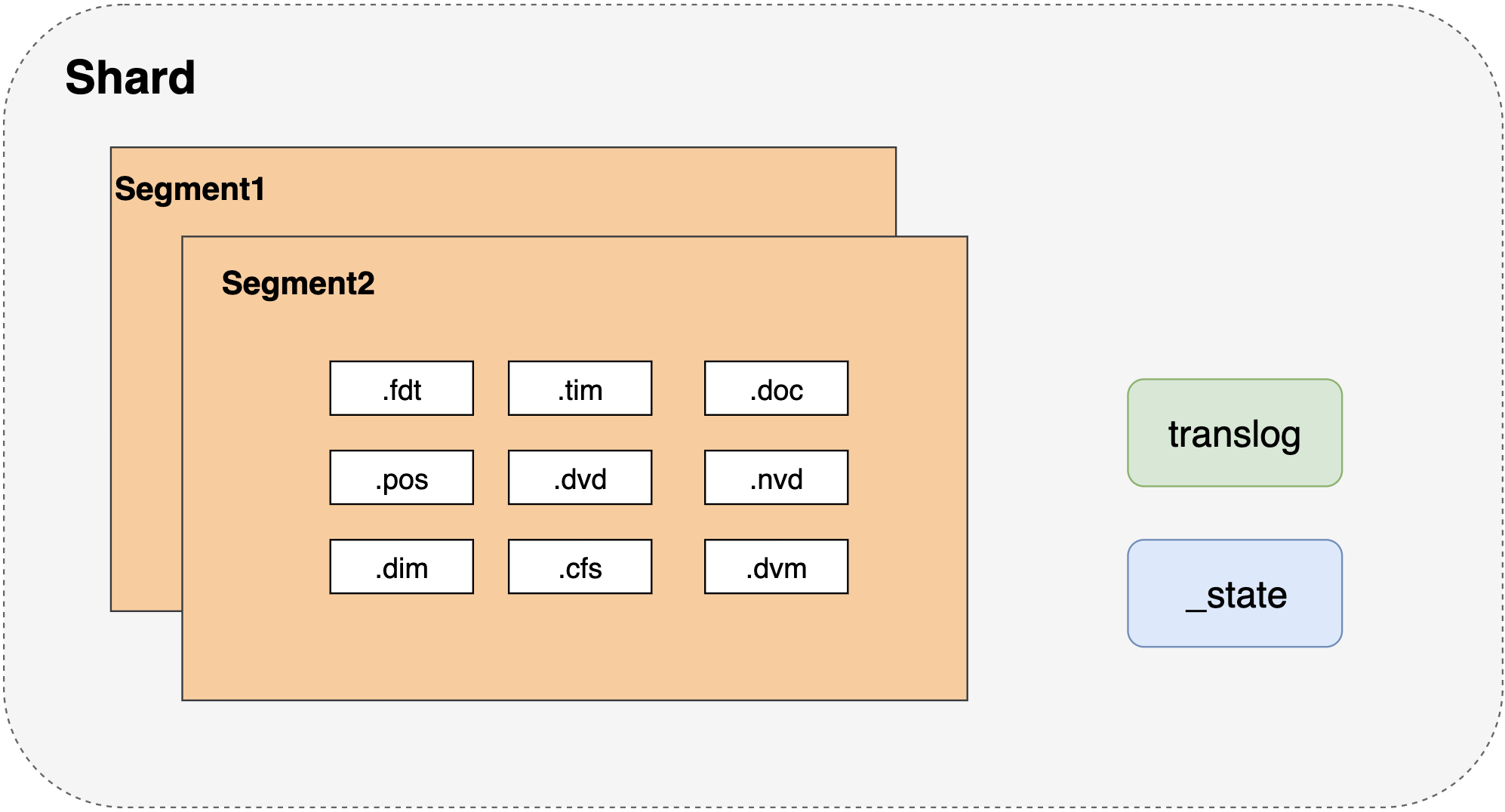
以一个40G索引为例子,如下:
| 文件类型 | 文件意义 | 磁盘占比 | |
|---|---|---|---|
| 1 | .tim | 倒排索引的数据文件,索引具体内容,包含词项词典,存储术语信息 | 较大3G |
| 2 | .tip | 倒排索引的索引文件 | 8M |
| 3 | .fdx | 正排存储文件的元数据信息 | 1.2M |
| 4 | .fdt | 存储了正排索引的数据,写入的原文件在这里 | 较大,1.5G |
| 5 | .pos | 全文索引的字段,会有该文件,保存了term在doc中的位置 | 800M |
| 6 | .dvd,.dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 | 42M |
| 7 | .doc | 保存了每个term的doc id列表和term在doc中的词频 | 占比较大300M |
| 8 | .nvd,.nvm | 文件保存索引字段加权数据 | 特别小8M |
| 9 | segments_N | 保存了索引包含的多少段,每个段包含多少文档 | |
| 10 | .cfs | 在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
最核心的文件
-
fdx,fdt存储正排索引数据,即FiledData
Doc Terms(Address) Doc1 USA Doc1 CA Doc1 WestStreet Doc2 USA Doc2 LA Doc3 China Doc3 Jiangsu Doc3 Suzhou Doc4 China Doc4 Jiangsu Doc4 Nanjing -
.dvd,.dvm存储列文件,即docValue,如下为一个列式存储结构
Doc Terms(Age) Doc1 33 Doc2 13 Doc3 19 Doc4 15 Doc5 11 -
tim,tip存储倒排索引数据根据,结构如下: