
Discovery模块负责发现集群中的节点,以及选择主节点。ES支持多种不同Discovery类型选择,内置的实现称为Zen Discovery,封装了节点发现(Ping)、选主等实现过程。
ES目前主要推荐的自动发现机制,有如下几种:
- Azure classic discovery{:target="_blank"} 插件方式,多播
- EC2 discovery{:target="_blank"} 插件方式,多播
- Google Compute Engine (GCE) discovery{:target="_blank"} 插件方式,多播
Zen discovery默认实现,多播/单播
单播,多播,广播的区别:
- 单播(unicast):网络节点之间的通信就好像是人们之间的对话一样。如果一个人对另外一个人说话,那么用网络技术的术语来描述就是“单播”,此时信息的接收和传递只在两个节点之间进行。例如,你在收发电子邮件、浏览网页时,必须与邮件服务器、Web服务器建立连接,此时使用的就是单播数据传输方式。
- 多播(multicast):“多播”也可以称为“组播”,多播”可以理解为一个人向多个人(但不是在场的所有人)说话,这样能够提高通话的效率。因为如果采用单播方式,逐个节点传输,有多少个目标节点,就会有多少次传送过程,这种方式显然效率极低,是不可取的。如果你要通知特定的某些人同一件事情,但是又不想让其他人知道,使用电话一个一个地通知就非常麻烦。多播方式,既可以实现一次传送所有目标节点的数据,也可以达到只对特定对象传送数据的目的。多播在网络技术的应用并不是很多,网上视频会议、网上视频点播特别适合采用多播方式。
- 广播(broadcast):可以理解为一个人通过广播喇叭对在场的全体说话,这样做的好处是通话效率高,信息一下子就可以传递到全体,广播是不区分目标、全部发送的方式,一次可以传送完数据,但是不区分特定数据接收对象。
为什么使用主从模式
除主从(Leader/Follower)模式外,另一种选择是分布式哈希表 (DHT),可以支持每小时数千个节点的离开和加入,其可以在不了解底层网络拓扑的异构网络中工作,查询响应时间大约为4到10跳(中转次数),例如Cassandra就使用这种方案。但是在相对稳定的对等网络中,主从模式会更好。
为什么主从模式更适合ES:
- ES集群中没有那么多节点;
- 节点的数量远远小于单个节点连接数;
- 网络环境不必经常处理节点的加入和离开;
选举算法
Bully算法
Leader选举的基本算法之一。它假定所有节点都有一个唯一的ID, 使用该ID对节点进行排序。任何时候的当前Leader都是参与集群的最高ID节点。 优点:易于实现。 缺点:当拥有最大ID的节点处于不稳定状态的场景下会有问题。例如,Master负载过重而假死,集群拥有第二大ID的节点被选为新主,这时原来的Master恢复,再次被选为新主,然后又假死......ES通过推迟选举,直到当前的 Master 失效来解决上述问题,只要当前主节点不挂掉,就不重新选主。但是容易产生脑裂(双主),为此,再通过『法定得票人数过半』解决脑裂问题。
脑裂现象
同时如果由于网络或其他原因导致集群中选举出多个Master节点,使得数据更新时出现不一致,这种现象称之为脑裂,即集群中不同的节点对于master的选择出现了分歧,出现了多个master竞争。
“脑裂”问题可能有以下几个原因造成:
网络问题:集群间的网络延迟导致一些节点访问不到master,认为master挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片。
节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应(假死状态)造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
内存回收:主节点的角色既为master又为data,当data节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应。
为了避免脑裂现象的发生,我们可以从原因着手通过以下几个方面来做出优化措施:
- 适当调大响应时间,减少误判 通过参数
discovery.zen.ping_timeout设置节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如6s,discovery.zen.ping_timeout:6),可适当减少误判。- 选举触发 我们需要在候选集群中的节点的配置文件中设置参数
discovery.zen.munimum_master_nodes的值,这个参数表示在选举主节点时需要参与选举的候选主节点的节点数,默认值是1,官方建议取值(master_eligibel_nodes/2) + 1,其中master_eligibel_nodes为候选主节点的个数。这样做既能防止脑裂现象的发生,也能最大限度地提升集群的高可用性,因为只要不少于discovery.zen.munimum_master_nodes个候选节点存活,选举工作就能å正常进行。当小于这个值的时候,无法触发选举行为,集群无法使用,不会造成分片混乱的情况。- 角色分离 即是上面我们提到的候选主节点和数据节点进行角色分离,这样可以减轻主节点的负担,防止主节点的假死状态发生,减少对主节点“已死”的误判。
Paxos算法
优点:在什么时机,以及如何进行选举方面的灵活性比简单的Bully算法有很大的优势,因为现实中存在比网络连接异常更多的故障模式。 缺点:实现起来非常复杂。
ES7.x使用了raft协议来进行选主,实现了亚秒级的master选举时间,并且ES的master节点选主去掉了minimum_master_nodes设置,减少了系统错误配置引发的脑裂风险,同时也提高了集群健壮性。
相关配置
与选主过程相关的重要配置有下列几个,并非全部配置。
-
discovery.zen.minimum_master_nodes:最小主节点数,这是防止脑裂、防止数据丢失的极其重要的参数。这个参数的实际作用早已超越了其表面的含义。除了在选主时用于决定『多数』,还用于多处重要的判断,至少包含以下时机:-
触发选主:进入选主的流程之前,参选的节点数需要达到法定人数。
-
决定Master:选出临时的Master之后,这个临时Master需要判断加入它的节点达到法定人数,才确认选主成功。
-
gateway选举元信息:向有Master资格的节点发起请求,获取元数据,获取的响应数量必须达到法定人数,也就是参与元信息选举的节点数。
-
Master发布集群状态:发布成功数量为多数。 为了避免脑裂,它的值应该是半数以上(quorum): (master_eligible_nodes / 2) + 1。例如,如果有3个具备Master资格的节点,则这个值至少应该设置为(3/2)+ 1 = 2。 该参数可以动态设置:
- PUT /_cluster/settings { "persistent" : { "discovery.zen.minimum_master_nodes":2 } }
-
-
discovery.zen.ping.unicast.hosts:集群的种子节点列表,构建集群时 本节点会尝试连接这个节点列表,那么列表中的主机会看到整个集群中 都有哪些主机。可以配置为部分或全部集群节点。可以像下面这样指定,默认使用9300端口,如果需要更改端口号,则可以在IP后手工指定 端口。也可以设置一个域名,让该域名解析到多个IP地址,ES会尝试连 接这个IP列表中的全部地址。discovery.zen.ping.unicast.hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com -
discovery.zen.ping.unicast.hosts.resolve_timeout:DNS 解析超时时间, 默认为5秒。 -
discovery.zen.join_timeout:节点加入现有集群时的超时时间,默认 为 ping_timeout的20倍。 -
discovery.zen.join_retry_attempts join_timeout:超时之后的重试次 数,默认为3次。 -
discovery.zen.join_retry_delay join_timeout:超时之后,重试前的延 迟时间,默认为100毫秒。 -
discovery.zen.master_election.ignore_non_master_pings:设置为true 时,选主阶段将忽略来自不具备Master资格节点(node.master: false)的 ping请求,默认为false。 -
discovery.zen.fd.ping_interval:故障检测间隔周期,默认为1秒。 -
discovery.zen.fd.ping_timeout:故障检测请求超时时间,默认为30 秒。 -
discovery.zen.fd.ping_retries:故障检测超时后的重试次数,默认为3 次。
节点的角色
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件../config/elasticsearch.yml中设置即可,默认都为true。
node.master: true //是否候选主节点
node.data: true //是否数据节点
数据节点负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作,所以数据节点(data节点)对机器配置要求比较高,对CPU、内存和I/O的消耗很大。通常随着集群的扩大,需要增加更多的数据节点来提高性能和可用性。
候选主节点可以被选举为主节点(master节点),集群中只有候选主节点才有选举权和被选举权,其他节点不参与选举的工作。主节点负责创建索引、删除索引、跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点、追踪集群中节点的状态等,稳定的主节点对集群的健康是非常重要的。
一个节点既可以是候选主节点也可以是数据节点,但是由于数据节点对CPU、内存核I/0消耗都很大,所以如果某个节点既是数据节点又是主节点,那么可能会对主节点产生影响从而对整个集群的状态产生影响。因此为了提高集群的健康性,我们应该对Elasticsearch集群中的节点做好角色上的划分和隔离。可以使用几个配置较低的机器群作为候选主节点群。
主节点和其他节点之间通过Ping的方式互检查,主节点负责Ping所有其他节点,判断是否有节点已经挂掉。其他节点也通过Ping的方式判断主节点是否处于可用状态。
虽然对节点做了角色区分,但是用户的请求可以发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发,这种节点可称之为协调节点,协调节点是不需要指定和配置的,集群中的任何节点都可以充当协调节点的角色。
流程概述
Zen Discovery的选主过程如下:
- 每个节点计算最小的已知节点ID,该节点为临时Master。向该节点发送领导投票。
- 如果一个节点收到足够多的票数,并且该节点也为自己投票,那么它将扮演领导者的角色,开始发布集群状态。
- 所有节点都会参与选举,并参与投票,但是只有有资格成为Master的节点(node.master为true)的投票才有效。
- 获得多少选票可以赢得选举胜利,就是所谓的法定人数。在 ES 中,法定大小是一个可配置的参数:
discovery.zen.minimum_master_nodes。为了避免脑裂,最小值应该是有Master资格的节点数n/2+1。
流程分析
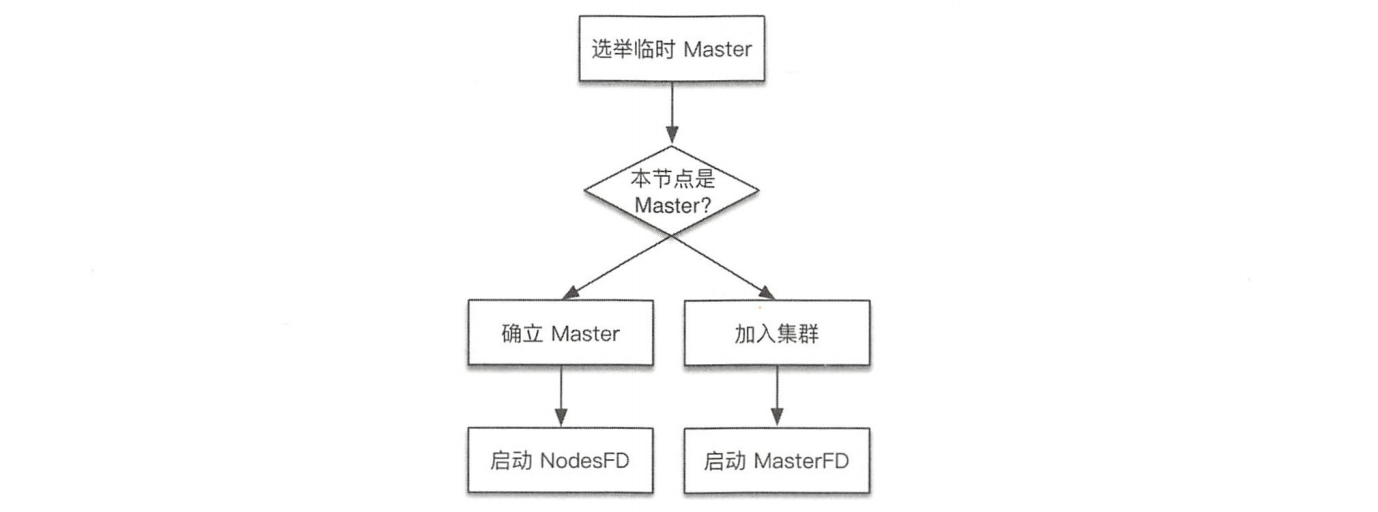
选举临时Master
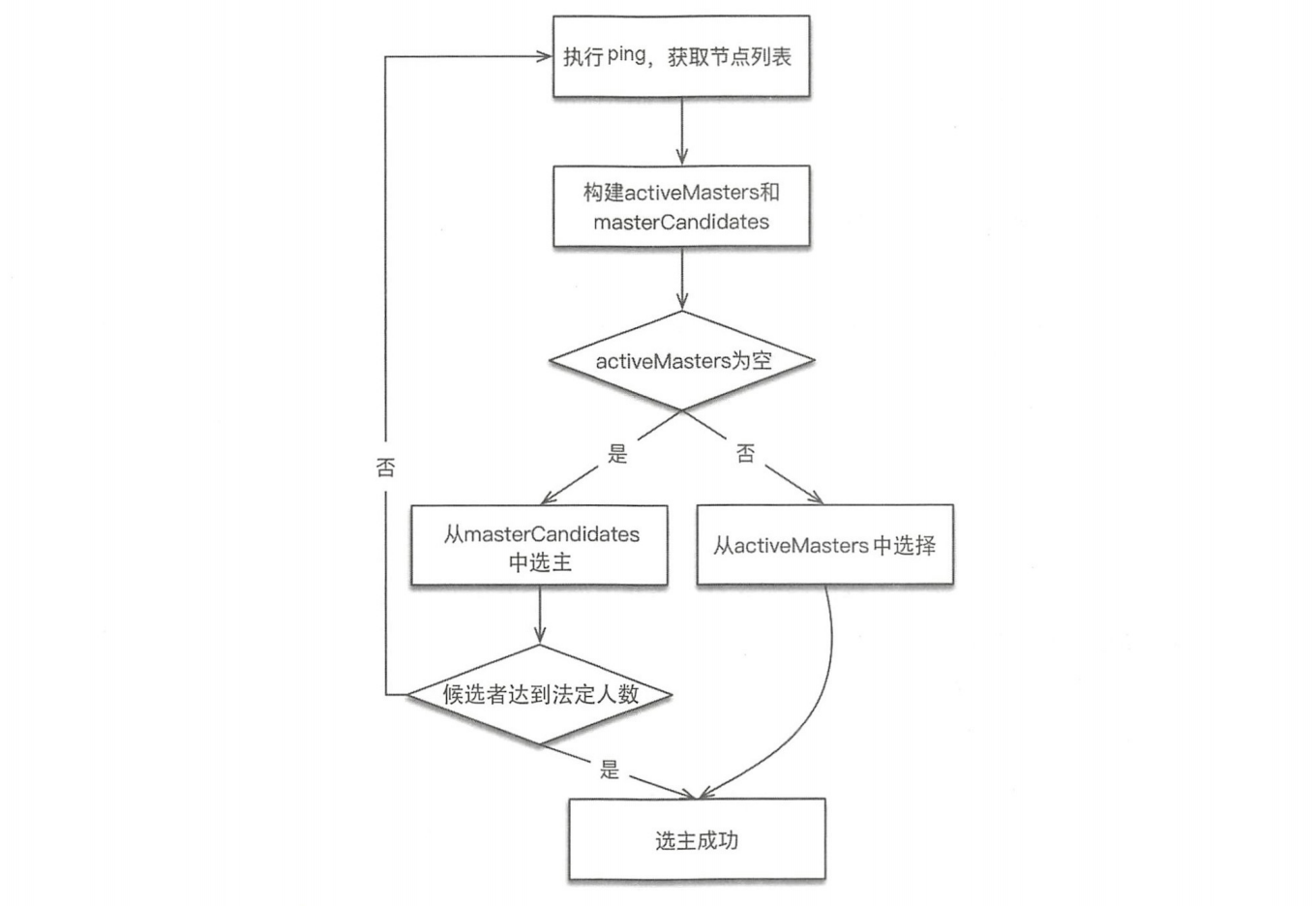
实现位于ZenDiscovery#findMaster。选举过程:
-
『ping』所有节点,获取节点列表fullPingResponses,ping结果不包含本节点,把本节点单独添加到fullPingResponses中。
-
构建两个列表。
-
activeMasters列表:存储集群当前活跃Master列表。遍历第一步获取的所有节点,将每个节点所认为的当前Master节点加入activeMasters 列表中(不包括本节点)。在遍历过程中,如果配置了 discovery.zen.master_election.ignore_non_master_pings 为 true(默认为 false),而节点又不具备Master资格,则跳过该节点。整体流程如下图所示:这个过程是将集群当前已存在的Master加入activeMasters列表,正常情况下只有一个。如果集群已存在Master,则每个节点都记录了当前Master是哪个,考虑到异常情况下,可能各个节点看到的当前Master不同。在构建activeMasters列表过程中,如果节点不具备Master资格,则可以通过
ignore_non_master_pings选项忽略它认为的那个Master。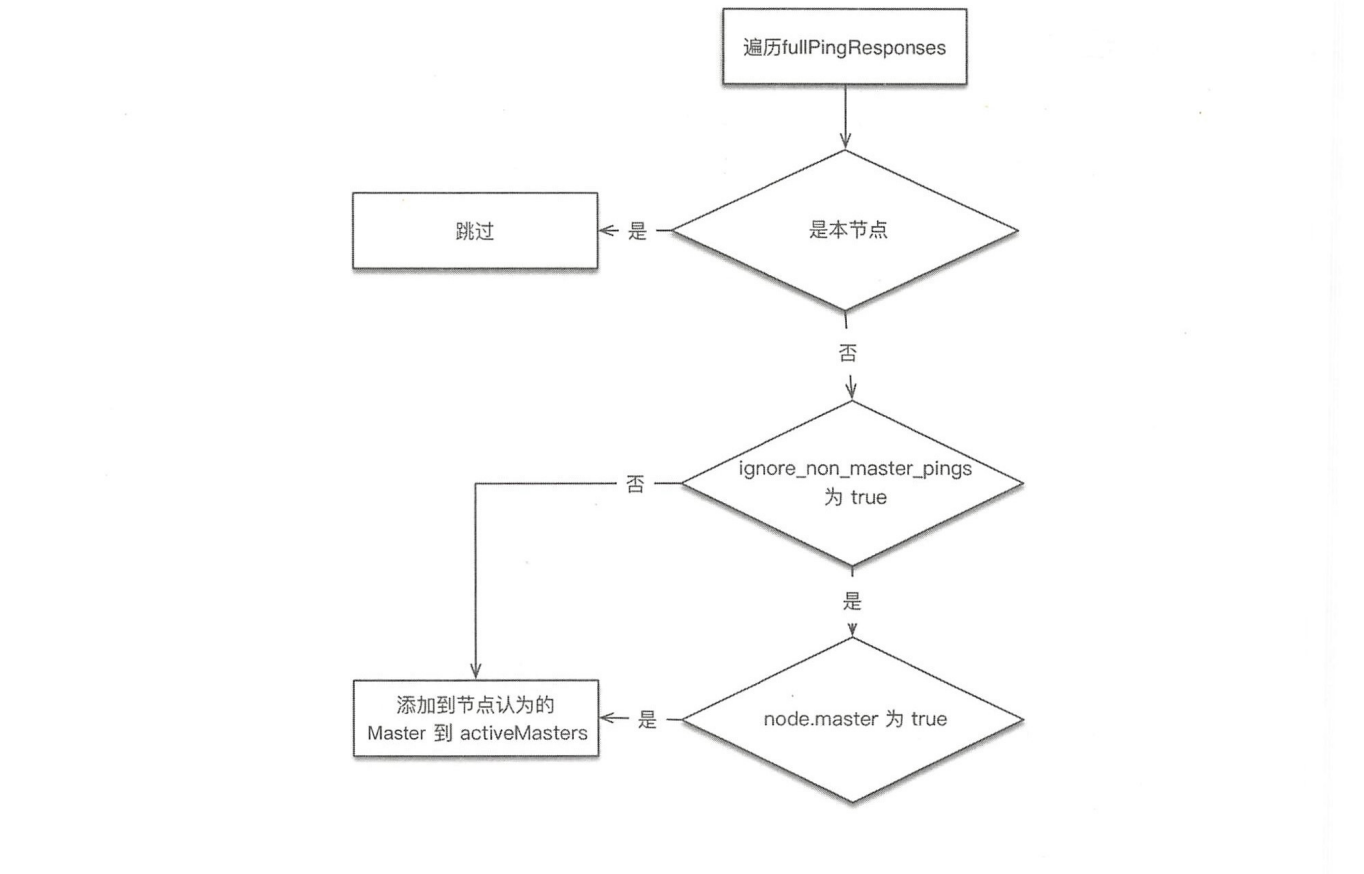
-
masterCandidates列表:存储master候选者列表。遍历第一步获取列表,去掉不具备Master资格的节点,添加到这个列表中。
-
-
如果activeMasters为空,则从masterCandidates中选举,结果可 能选举成功,也可能选举失败。如果不为空,则从activeMasters中选择最合适的作为Master。整体流程如下图所示:
投票与得票
发送投票就是发送加入集群(JoinRequest)请求。得票就是申请加入该节点的请求的数量。
收集投票,进行统计的实现在ZenDiscovery#handleJoinReques方法中,收到的连接被存储到ElectionContext#joinRequestAccumulator中。当节点检查收到的投票是否足够时,就是检查加入它的连接数是否足够, 其中会去掉没有Master资格节点的投票。
public synchronized int getPendingMasterJoinsCount() {
int pendingMasterJoins = 0;
//遍历当前收到的join请求
for (DiscoveryNode node : joinReques tAccumulator .keySet()) {
//过滤不具备master资格的节点
if (node. isMasterNode()) {
pendingMasterJoins++;
}
}
return pendingMasterJoins;
}
确立Master或加入集群
选举出的临时Master有两种情况:该临时Master是本节点或非本节点。为此单独处理。现在准备向其发送投票。
如果临时Master是本节点:
- 等待足够多的具备Master资格的节点加入本节点(投票达到法定人数),以完成选举。
- 超时(默认为30秒,可配置)后还没有满足数量的join请求,则选举失败,需要进行新一轮选举。
- 成功后发布新的clusterState。
如果其他节点被选为Master:
- 不再接受其他节点的join请求。
- 向Master发送加入请求,并等待回复。超时时间默认为1分钟(可配置),如果遇到异常,则默认重试了3次(可配置)。这个步骤在joinElectedMaster方法中实现。
- 最终当选的Master会先发布集群状态,才确认客户的join请求,因此, joinElectedMaster返回代表收到了join请求的确认,并且已经收到了集群状态。本步骤检查收到的集群状态中的Master节点如果为空,或者当选的Master不是之前选择的节点,则重新选举。
节点失效检测
到此为止,选主流程已执行完毕,Master 身份已确认,非Master节点已加入集群。节点失效检测会监控节点是否离线,然后处理其中的异常。失效检测是选主流程之后不可或缺的步骤,不执行失效检测可能会产生脑裂(双主或多主)。在此我们需要启动两种失效探测器:
- 在Master节点启动NodesFaultDetection,简称NodesFD。定期探测加入集群的节点是否活跃。
- 在非Master节点启动MasterFaultDetection,简称MasterFD。定期探测Master节点是否活跃。
NodesFaultDetection和MasterFaultDetection都是通过定期(默认为1秒)发送的ping请求探测节点是否正常的,当失败达到一定次数(默认为3次),或者收到来自底层连接模块的节点离线通知时,开始处理节点离开事件。
NodesFaultDetection 事件处理
检查一下当前集群总节点数是否达到法定节点数(过半),如果不足,则会放弃Master身份,重新加入集群。为什么要这么做?设想下面的场景,如下图所示:

假设有5台机器组成的集群产生网络分区,2台组成一组,另外3台组成一组,产生分区前,原Master为Node1。此时3台一组的节点会重新选举并成功选取Noded3作为Master,会不会产生双主?NodesFaultDetection就是为了避免上述场景下产生双主。
对应事件处理主要实现如下:在ZenDiscovery#handleNodeFailure中执行NodeRemoval-ClusterStateTaskExecutor#execute。
public ClusterTasksResult<Task> execute (final ClusterState currentState, final List<Task> tasks) throws Exception {
//判断剩余节 点是否达到法定人数
if (electMasterService.hasEnoughMasterNodes (remainingNodesClusterState.nodes()) == false) {
final int masterNodes = electMas terService.countMasterNodes(remainingNodesClusterState.nodes());
rejoin.accept(LoggerMessageFormat.format("not enough master nodes(has [{}], but needed [{}])", masterNodes, electMasterService.minimumMasterNodes()));
return resultBuilder .build (currentState) ;
} else {
return resultBuilder.build (allocationService.deassociateDeadNodes(remainingNodesClusterState, true, describeTasks(tasks)));
}
}
主节点在探测到节点离线的事件处理中,如果发现当前集群节点数量不足法定人数,则放弃Master身份,从而避免产生双主。
MasterFaultDetection事件处理
探测Master离线的处理很简单,重新加入集群。本质上就是该节点重新执行一遍选主的流程。对应事件处理主要实现如下: ZenDiscovery#handleMasterGone
private void handleMasterGone (final DiscoveryNode masterNode, final Throwable cause, final String reason) {
synchronized(stateMutex) {
if (localNodeMaster() == false && masterNode.equals (committedState.get().nodes ().getMasterNode())) {
pendingStatesQueue.failAllStatesAndClear (new ElasticsearchException("master left[[)]", reason));
//重新加入集群
rejoin ("master left (reason = " + reason + ")");
}
}
}
小结
选主流程在集群中启动,从无主状态到产生新主时执行,同时集群在正常运行过程中,Master探测到节点离开,非Master节点探测到Master离开时都会执行。