
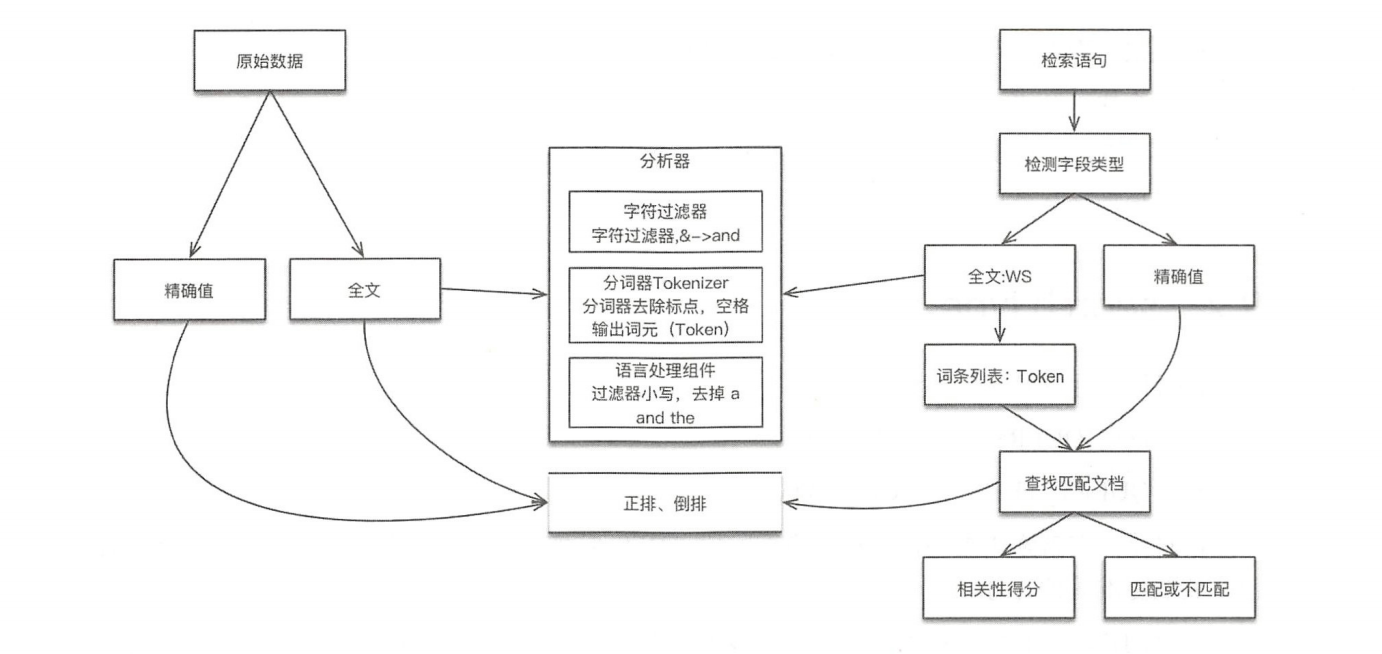
索引和搜索
ES 中的数据可以分为两类精确值(Exact Values)、全文本(Full Text):
- 精确值:包括数字,日期,一个具体字符串(例如"Hello World”)。
- 在 ES 中用 keyword、numeric数据类型表示。
- 精确值不需要做分词处理;
- 精确值比较是二进制的,要么匹配,要么不匹配。
- 全文本:非结构化的文本数据。
- 在 ES 中用 **text**数据类型表示。
- 全文本需要做分词处理;
- 全文本查询找到的是"看起来像"你要的查询东西。
分词主要用于建立单词(Term / Token)与倒排索引对应关系,比如将
hello world拆分为hello和world。
对数据建立索引和执行搜索原理:
分布式搜索过程
收到查询请求的节点可以叫协调节点,分为查询(Query) 阶段和取回(Fetch)阶段。
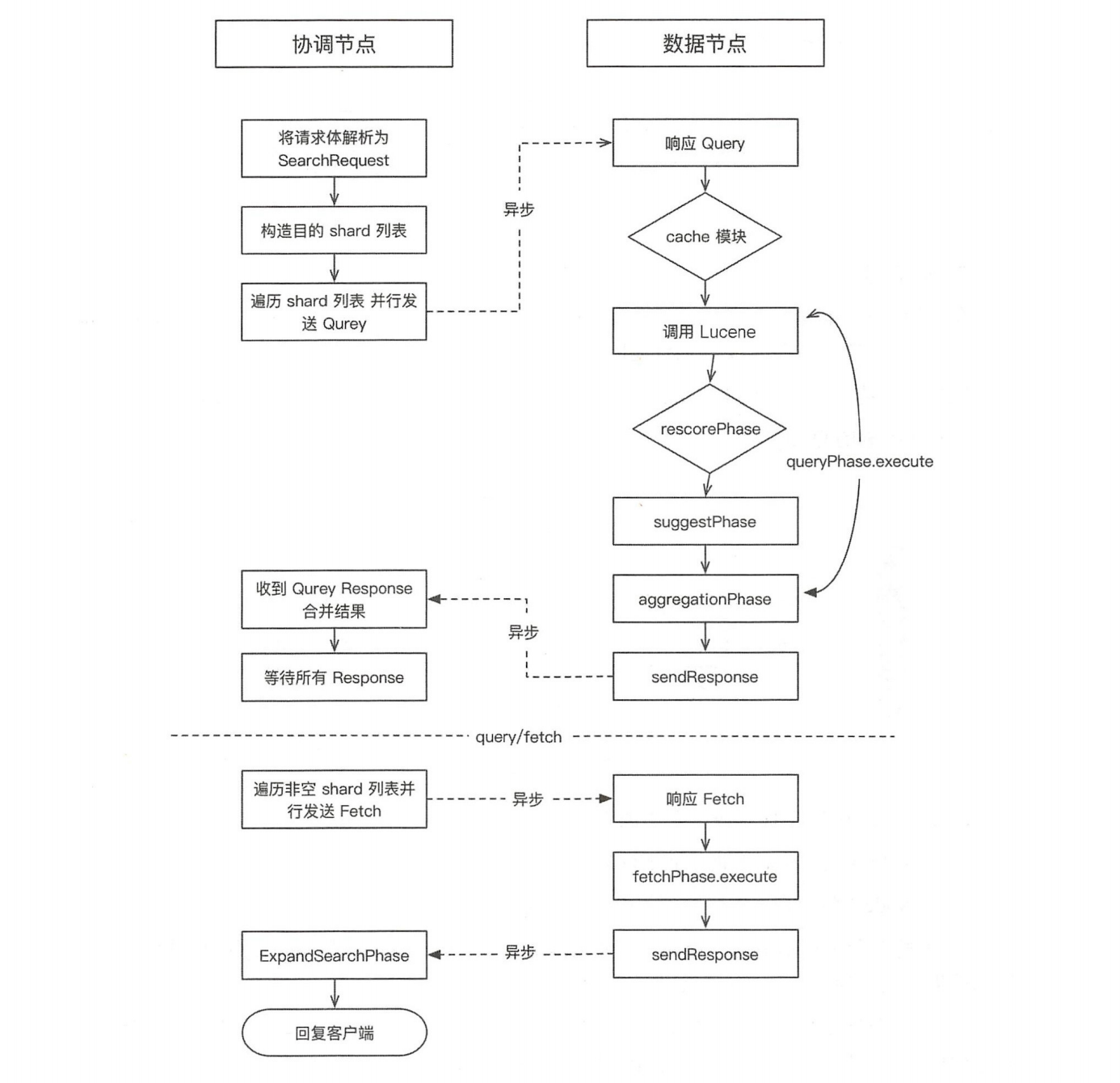
Query阶段:
QUERY_THEN_FETCH:(默认的搜索方式)
- 除去直接路由的查询,协调节点会把查询广播到索引的所有分片(数据节点):主分片或者是副本分片;
- 数据节点在本地执行查询,并使用本地的Term/Document Frequency信息进行打分,添加结果到大小为from + size的本地有序优先队列中;
- 数据结果返回的是文档的ID和排序值,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表;
- Query阶段并不会对搜索请求的内容进行解析,无论搜索什么内容,只看本次搜索需要命中哪些shard,然后针对每个特定shard选择一个副本,转发搜索请求。
协调节点首先决定哪些文档“确实”需要被取回,例如,如果查询指定了{ "from": 90, "size":10 },则只有从第91个开始的10个结果需 要被取回。为了避免在协调节点中创建的number_of_shards * (from + size)优先队列过大,应尽量控制分页深度。
执行本流程的线程池:http_server_work。
搜索速度优化
搜索请求中的batched_reduce_size
该字段是搜索请求中的一个参数。默认情况下,聚合操作在协调节点需要等所有的分片都取回结果后才执行,使用 batched_reduce_size 参数可以不等待全部分片返回结果,而是在指定数量的分片返回结果之后 就可以先处理一部分(reduce)。这样可以避免协调节点在等待全部结 果的过程中占用大量内存,避免极端情况下可能导致的OOM。该字段的默认值为512,从ES 5.4开始支持。
自适应副本选择(ARS)
例如,一个分片的三个副本分布在三个节点上,其中Node2可能因 为长时间GC、磁盘I/O过高、网络带宽跑满等原因处于忙碌状态,如下 图所示。

如果搜索请求被转发到副本2,则会看到相对于其他分片来说,副 本2有更高的延迟。
- 分片副本1:100ms。
- 分片副本2(degraded):1350ms。
- 分片副本3:150ms。
由于副本2的高延迟,使得整个搜索请求产生长尾效应。
ES希望这个过程足够智能,能够将请求路由到其他数据副本,直到该节点恢复到足以处理更多搜索请求的程度。在ES中,此过程称为『自适应副本选择』。
在实现过程中,ES参考一篇名为 C3的论文: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection 。这篇论文是为Cassandra写的,ES基于这篇论文的思想做了调整以适合自己的场景。
ES的ARS实现基于这样一个公式:对每个搜索请求,将分片的每个副本进行排序,以确定哪个最可能是转发请求的『最佳』副本,将请求路由到那里。ARS公式为: $$ \Psi(s)=R(s)-\frac{1}{\overline{\mu}(s)}+\frac{(\hat{q}(s))^3}{\overline{\mu}(s)} \ \hat{q}(s)=1+(os(s)*n)+q(s) $$
每项含义如下:
- os(s):节点未完成的搜索请求数;
- n: 系统中数据节点的数量;
- q(s):搜索线程池队列中等待任务数量的EWMA;
- R(s):响应时间的EWMA (从协调节点上可以看到),单位为毫秒;
- μ(s):数据节点上的搜索服务时间的EWMA,单位为毫秒。
关于EWMA的解释可参考:https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average
ARS从6.1版本开始支持,但是默认关闭,可以通过下面的命令动态开启:
PUT /_cluster/settings
{
"transient": {
"cluster.routing.use_adaptive_replica_selection": true
}
}
从ES 7.0开始,ARS将默认开启。官方进行了多种场景的基准测试,包括某个数据节点处于高负载状态和非负载状态,测试使用5节点的集群,单个索引,5个主分片,每个主分片有一个副分片。模拟单个节点处于高负载下的情况,指标如下表所示。使用ARS,在某个数据节点处于高负载的情况下,吞吐量有了很大的提高。延迟中位数有所增加是预料之中的,为了绕开高负载的节点,稍微增加了无压力节点的负载,从而增加了延迟。
| 指标 | 不开启ARS | 开启ARS | 变化率(%) |
|---|---|---|---|
| 吞吐量中位数(查询/秒) | 41.1558 | 87.8231 | 113.4 |
| 延迟中位数 | 411.721 | 1007.22 | 144.6 |
| 第90个百分位的延迟(毫秒) | 5215.34 | 1839.46 | -64.7 |
| 第99个百分位的延迟(毫秒) | 6181.48 | 2433.55 | -60.6 |
numeric 还是keyword?
因为numeric支持等值精确查询,所以字段类型到底使用keyword还是numeric?答案是keyword。
numeric类型为了能有效的支持范围查询,它的存储结构并不是倒排索引。numeric类型从lucene6.0开始,使用了一种名为block KD tree的存储结构。Block KD tree介绍在这里,不过多阐述。
具体的ES内部(其实是Lucene)目前的版本是基于所谓的PointValues,比如整型在Lucene内部是IntPoint类表示,还有DoublePoint等,完整的对应关系是:
| Java type | Lucene class |
|---|---|
| int | IntPoint |
| long | LongPoint |
| float | DoublePoint |
| byte[] | BinaryPoint |
而这些PointValues是基于kd-tree存储的,根据官方文档的介绍,lucene把叶子节点在磁盘是顺序存储的,这样搜索的效率就会非常高。
为啥numeric对于term精确匹配的查询性能没有keyword好
前面我们提到了IntPoint类,这个类有三个查询方法:
//构造精确查询,内部还是调用newRangeQuery
Query newExactQuery(String field, int value)
//构造一维查询,内部是调用多维查询的方法
Query newRangeQuery(String field, int lowerValue, int upperValue)
//构造多维查询
Query newRangeQuery(String field, int[] lowerValue, int[] upperValue)
比如有这样一个索引:
PUT blogs
{
"mappings": {
"properties": {
"title": { "type": "keyword" },
"content": { "type": "text" },
"status": { "type": "integer" }
}
}
}
基于status查询
{
"query": {
"term": {
"title": {
"status": 2
}
}
}
}
在lucene内部其实还是进行了一个2~2的范围查询。即便kd-tree的性能也很高,但是对于这种精确查询还是要到树上走一遭,而倒排索引相当于是直接在内存里就定位到了结果集的文档id。如果是bool组合查询的话,term还可以利用跳表进行合并,这点numeric字段也是做不到的。